|
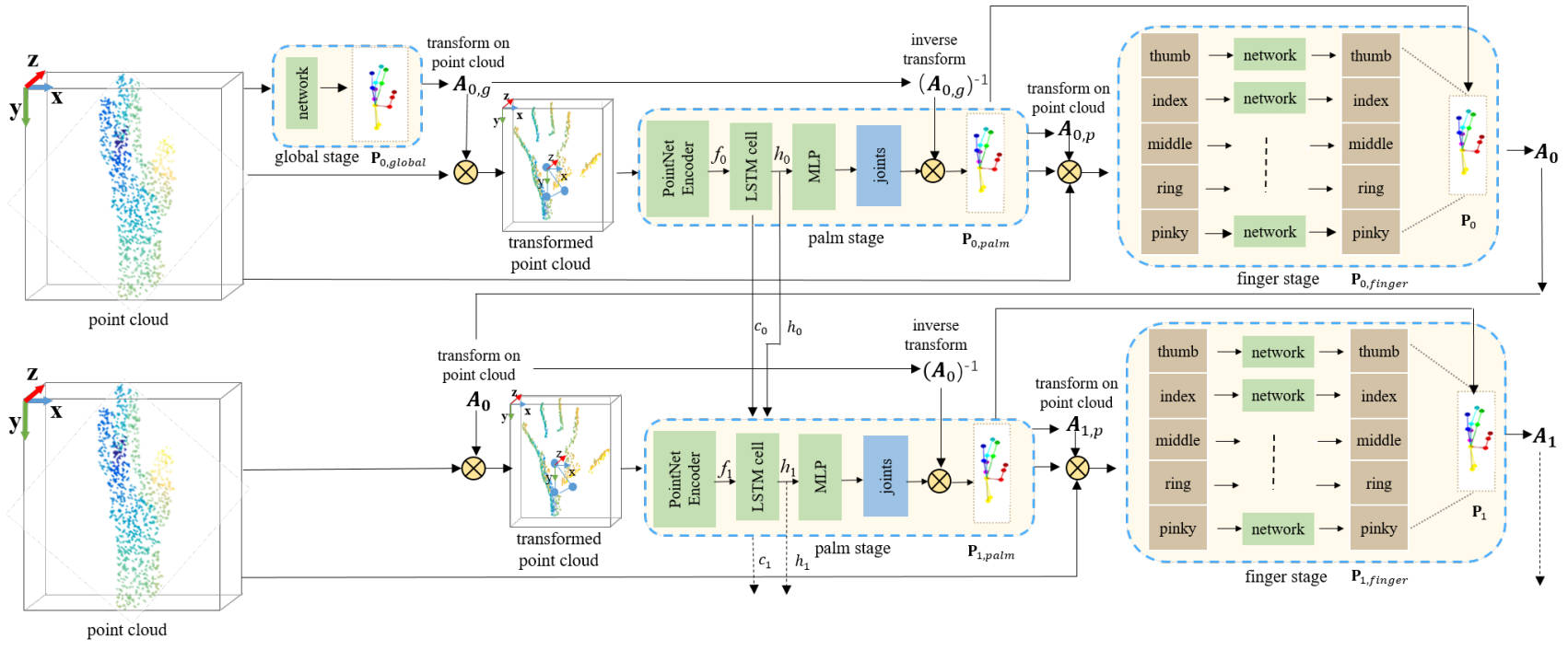
Illustration of our recurrent hand pose network using cascaded pose-guided alignments.
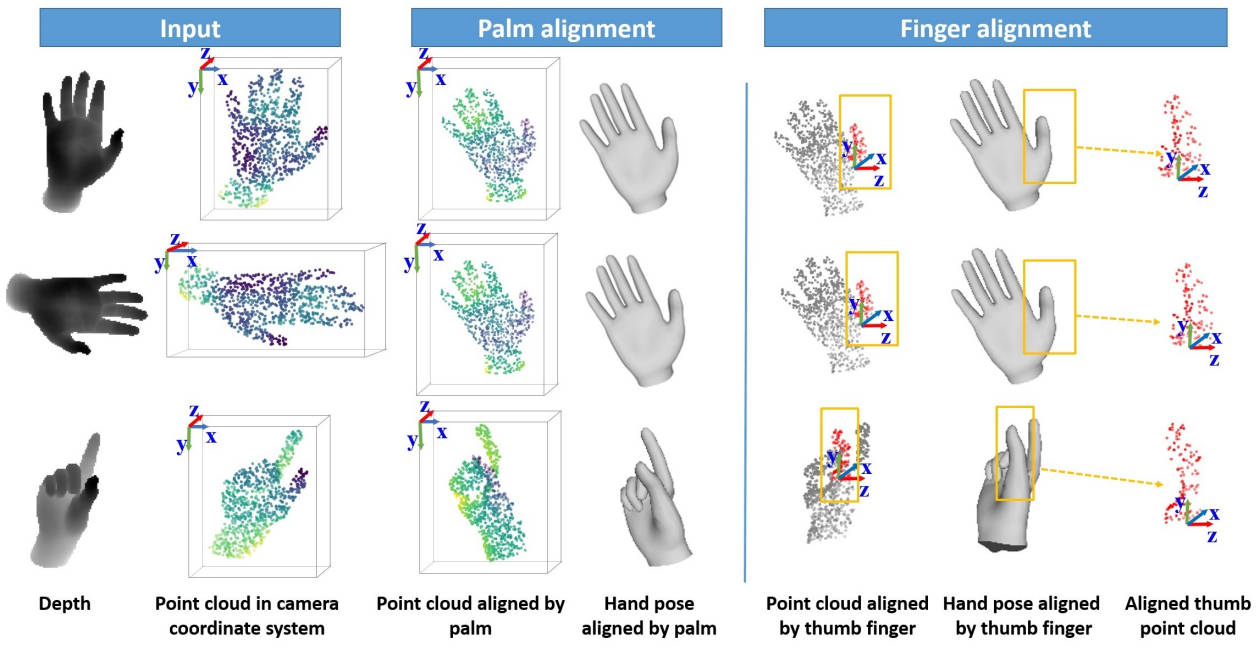
We first convert the input hand foreground depth to point cloud.
Then we adopt multiple recurrent iterations to estimate the 3D hand pose.
Specifically, we introduce several LSTM modules among multiple palm stages to refine the hand pose.
In each recurrent iteration, we adopt a multi-stage network (i.e. global, palm and finger stages) to
predict hand joints by iterative pose regression and cascaded pose-guided 3D alignment,
and we adopt the hand pose of the previous iteration to align the input point cloud of the current iteration.
“PointNet Encoder” denotes the network before the last multi-layer perception (MLP) of PointNet++.
“A0,g” is the transformation via the estimated hand pose P0,global of the global stage in the initial recurrent
iteration, “At,p” are the transformations to align each finger via the estimated hand pose of the
palm stage Pt,palm in the t-th recurrent iteration, and “At” is the transformation via the
composited hand pose “Pt” of the palm stage and the finger stage in the t-th recurrent iteration. “⊗” denotes matrix multiplication.
|