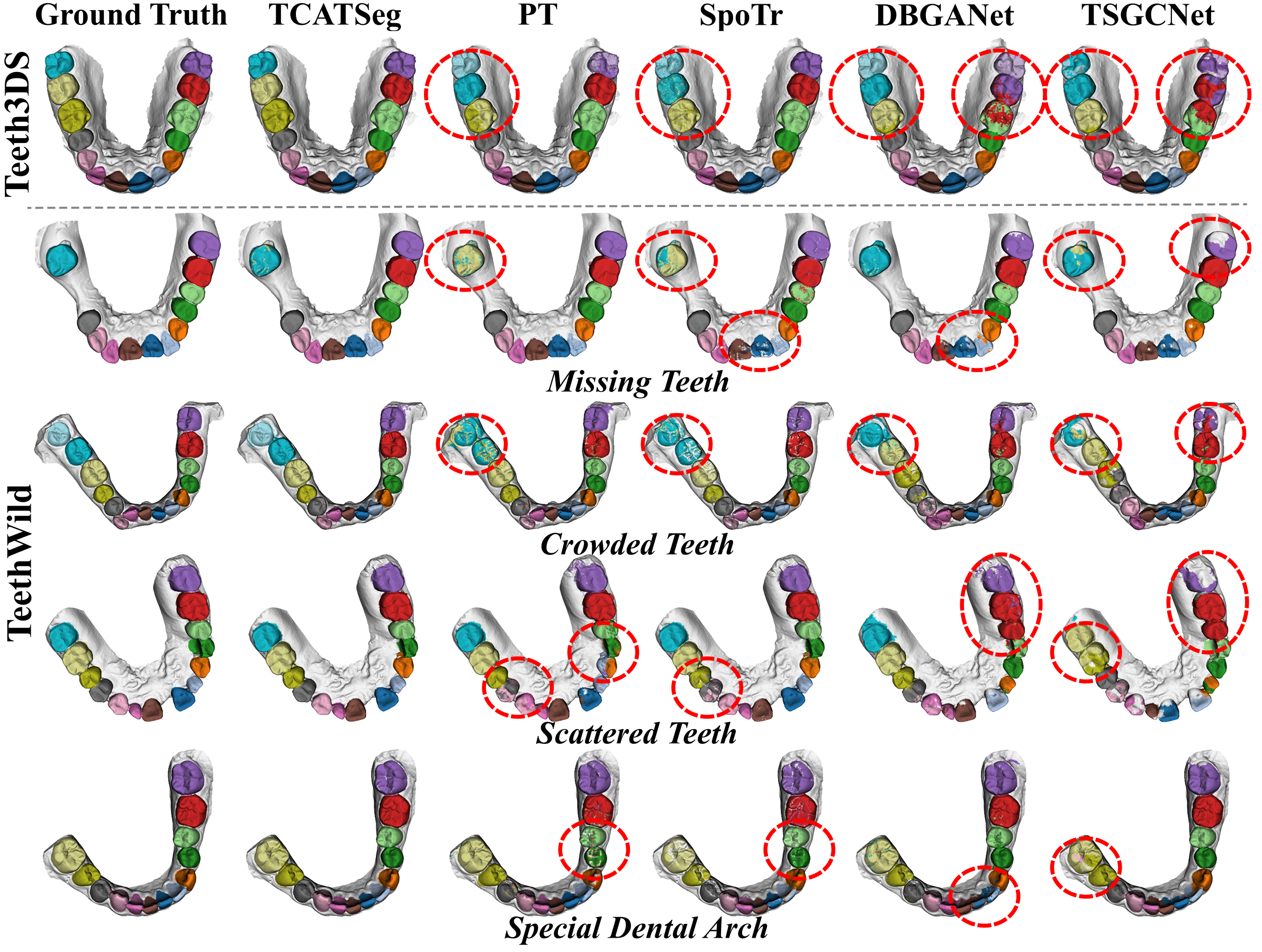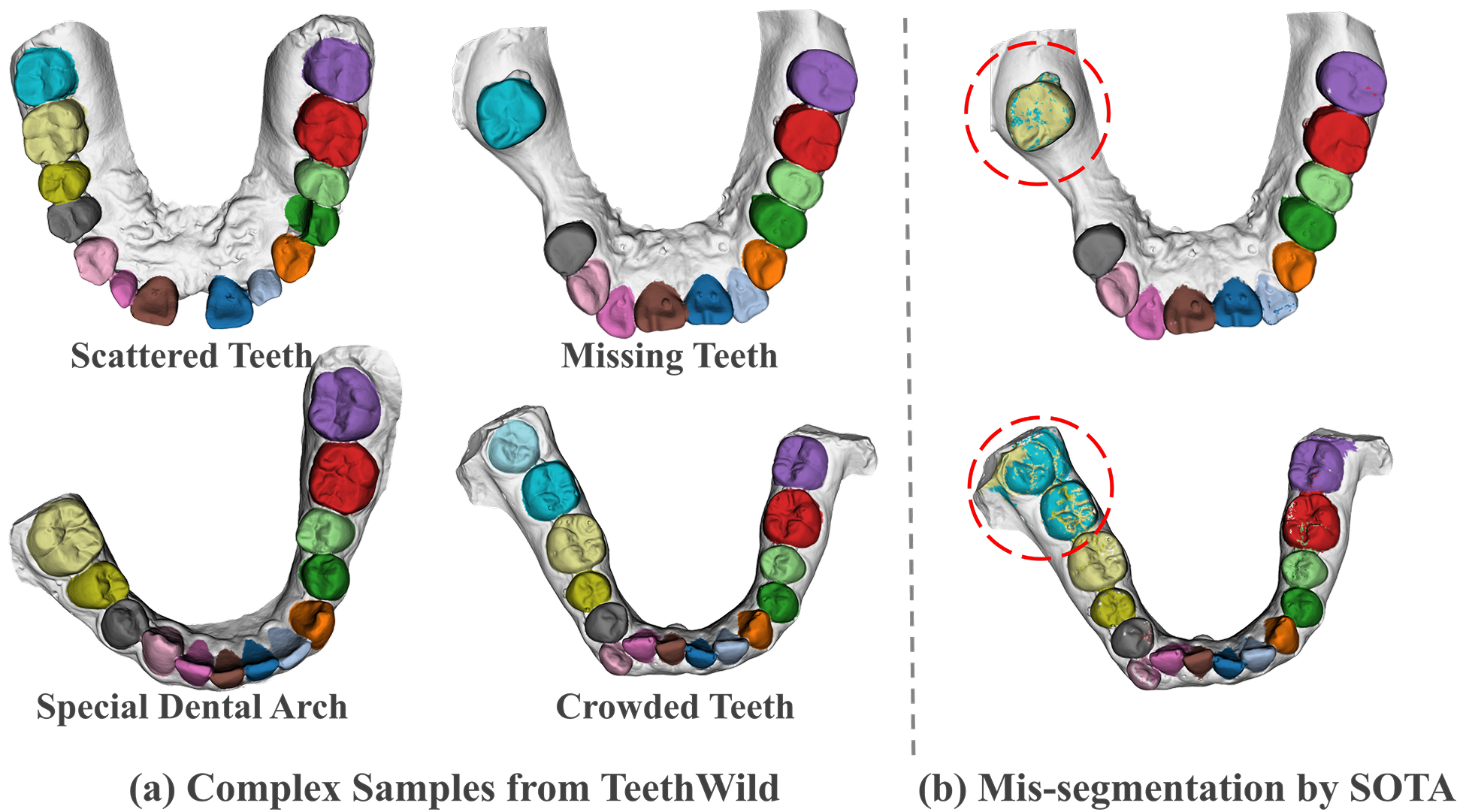
SOTA method struggles on our TeethWild dataset.
|
Qiang He1,2
|
Wentian Qu1,2
|
Jiajia Dai3
|
Changsong Lei3
|
Shaofeng Wang4
|
Feifei Zuo5
|
|
Yajie Wang5
|
Yaqian Liang3,†
|
Xiaoming Deng1,2
|
Cuixia Ma1,2,†
|
Yong-Jin Liu3
|
Hongan Wang1,2
|
|
1Institute of Software, Chinese Academy of Sciences
|
2University of Chinese Academy of Sciences
|
3Department of Computer Science and Technology, Tsinghua University
|
|
4Beijing Stomatological Hospital, Capital Medical University
|
5LargeV Instrument Corporation, Ltd.
|
|
|
|
SOTA method struggles on our TeethWild dataset.
|
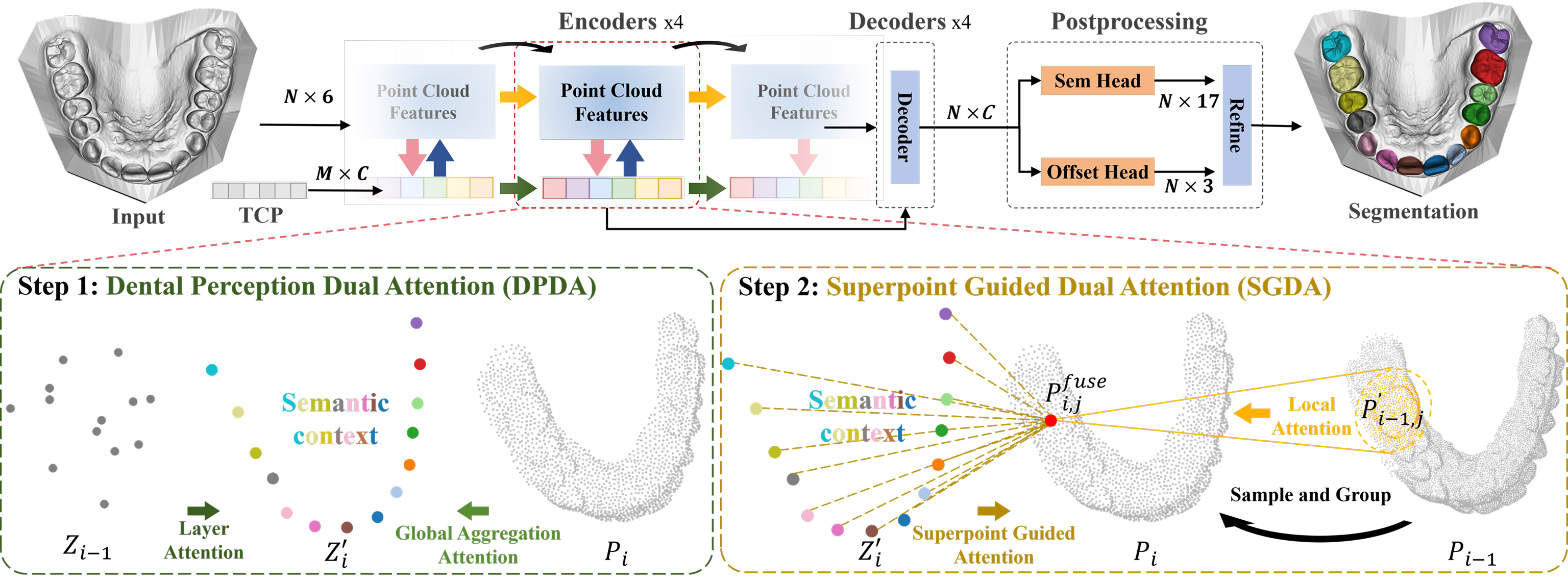
Accurate semantic segmentation of 3D dental models is essential for digital dentistry applications such as orthodontics and dental implants. However, due to complex tooth arrangements and similarities in shape among adjacent teeth, existing methods struggle with accurate segmentation because they often focus on local geometry while neglecting global contextual information. To address this, we propose TCATSeg, a novel framework that combines local geometric features with global semantic context. We introduce a set of sparse yet physically meaningful superpoints to capture global semantic relationships and enhance segmentation accuracy. Additionally, we present a new dataset of 400 dental models, including pre-orthodontic samples, to evaluate the generalization of our method. Extensive experiments demonstrate that TCATSeg outperforms state-of-the-art approaches.
|
|
In our conditional diffusion model, we use the given sequence of object motion, object shape and the SMPL-X identity as conditions. After specially designed positional encodings, these embedded conditions are inputted into a transformer-encoder-based condition encoder. Then, a transformer decoder as denoising network predicts a sequence of clean whole-body pose of SMPL-X as well as the wrist joints translations relative to the object centroid. During the inference stage, we reconstruct the SMPL-X pose sequence into a human mesh sequence. Based on carefully designed guidance functions, we control and optimize our predicted results for more stable hand grasping, less penetration and better foot-floor contact through reconstruction guidance strategy.
|

|
Q. He, W. Qu, J. Dai, C. Lei, S. Wang, F. Zuo, Y. Wang, Y. Liang, X. Deng, C. Ma, Y.-J. Liu, H. Wang
TCATSeg: A Tooth Center-Wise Attention Network for 3D Dental Model Semantic Segmentation. arXiv:2603.16620, 2026. [Paper] [Bibtex] [Code] |
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant Nos. 62272447, 62502337) and the Beijing Natural Science Foundation Haidian Original In novation Joint Fund (Grant Nos. L222008, L232028, and L242060).
The website is modified from this template. |